El paso de 24 de noviembre de 2015, alumnos de la carrera de ingeniería informática del Instituto Tecnológico Superior De Cintalapa, donde dios sita en una de las instituciones más prestigiadas del país, el Instituto Tecnológico De Monterrey Campus Puebla.
En dicho lugar se dio cita El Clúster Puebla Tic esta es una asociación de empresas del sector de las Tecnologías de la Información, Centros de Investigación e Instituciones de Educación Superior, desarrollando soluciones tecnológicas y generando fuentes de empleo calificadas.
El cual tiene la misión de fomentar la asociatividad para impulsar la innovación y la competitividad del sector de Tecnologías de la Información y obtener el reconocimiento a nivel internacional por la generación de soluciones tecnológicas especializadas y competitivas en el mercado.
El Clúster Puebla TIC agrupa a universidades y empresas mayormente desarrolladoras de software con diferentes especialidades. Algunas empresas cuentan con más de veinte años de experiencia.
En mi experiencia puedo mencionar una empresa de consultores de consultores donde destacaba la importancia de designar roles en cuanto la construcción de un proyecto informático, ya que hoy en día existen muchas empresas las cuales mas mayor parte de las veces no logran con el objetivo del proyecto o bien lo realizan en un tiempo mayor al planeado, esto se debe a la mala planeación del proyecto, gestionado por el proyect manager a cargo, me llamo más adelante la atención una empresa llamada “CERTEL” la cual principalmente hablaba sobre redes, pero lo inquietante fue que comentaba la importancia de la certificación , mencione que una de mis inquietudes era que cada persona tiene una capacidad distinta, en mi caso puedo decir que mi vocación no es encargarme de la programación al 100% en algún proyecto, pues debo decir que si es algo que voy a hacer toda mi vida mínimo me gustaría enfocarme en algo que sea de mi agrado y entero dominio , entonces el conferencista dijo que era importante principalmente conocer que capacidades tenemos, en que somos buenos y entonces después de ello buscar una certificación si, pero en aquello que somos buenos, en mi caso Manager Proyect. Y destacare que esta conferencia me ha impulsado para ir tras esa certificación que se que costara pero por ahora el propósito de seguir preparándome aún más ha crecido.
miércoles, 9 de diciembre de 2015
lunes, 30 de noviembre de 2015
UNIDAD V: Usos y tendencias de los Sistemas Distribuidos
5.1 Administración Sistemas Distribuidos
Los administradores de sistemas distribuidos se ocupan de monitorear continuamente al sistema y se deben de asegurar de su disponibilidad. Para una buena administración, se debe de poder identificar las áreas que están teniendo problemas así como de la rápida recuperación de fallas que se puedan presentar. La información que se obtiene mediante el monitoreo sirve a los administradores para anticipar situaciones críticas. La prevención de estas situaciones ayuda a que los problemas no crezcan para que no afecten a los usuarios del sistema.

5.1.1 Instalación de Sistemas Operativos Distribuidos
—El instalar un sistema operativo no es solo instalar un CD y ejecutarlo, ya que debe configurarse para blindarlo de amenazas y ofrecer mayor seguridad.
Una vez instalado el sistema operativo se deben realizar las siguientes acciones:
1. Verificar que el firewall esté habilitado y habilitarlo en caso contrario.
2. Actualizar a las últimas versiones del producto.
3. Verificar las actualizaciones automáticas
4. Habilitar la protección antivirus.
5. Crear un usuario con permisos no-administrativos y dejar el usuario "Administrador" sólo para tareas de instalación y mantenimiento
6. Deshabilitar algunos servicios del Sistema operativo para usuarios con acceso restringido.

Control Sod
—El Control de Sistemas e Informática, consiste en examinar los recursos, las operaciones, los beneficios y los gastos de las producciones, de los Organismos sujetos a control, con la finalidad de evaluar la eficacia y eficiencia Administrativa Técnica de los Organismos, en concordancia con los principios, normas, técnicas y procedimientos normalmente aceptados. Asimismo de los Sistemas adoptados por la Organización para su dinámica de Gestión en salvaguarda de los Recursos del Estado.

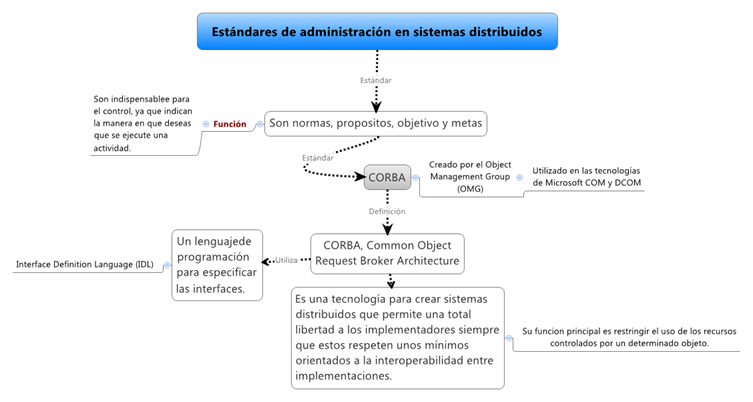
5.2 Estándares de administración de SOD
Los estándares son aquellas normas usuales, los propósitos, los objetivos, a alcanzar, las metas a alcanzar y aquellos índices que integran los planes, y todo dato o cifra que pueda emplearse como medida para cumplirlas, son considerados como estándares.
Estas medidas son indispensables para el control, ya que indican la manera en que deseas que se ejecute una actividad. En la práctica, son los objetivos declarados y definidos de la organización y por esa razón los estándares deben abarcar las funciones básicas y áreas clave de los resultados logrados.
Un estándar muy utilizado en los sistemas distribuidos es el CORBA, en el cual nos basaremos para explicar este tema.
CORBA es el estándar para la creación de sistemas distribuidos creado por el Object Management Group (OMG). Pensado para ser independiente del lenguaje, rápidamente aparecieron implementaciones en las que se podía usar casi cualquier lenguaje.
5.3 Tendencias de Investigación Sistemas Distribuidos
Una tendencia reciente en los sistemas de computador es distribuir el cómputo entre varios procesadores. En contraste con los sistemas fuertemente acoplados, los procesos no comparten ni la memoria ni el reloj. Los procesadores se comunican entre sí a través de diversas líneas de comunicación, como buses de alta velocidad o líneas telefónicas.
Los procesadores de estos sistemas pueden tener diferentes tamaños y funciones que pueden incluir microprocesadores pequeños, estaciones de trabajo, minicomputadoras y sistemas de computador de propósito general o distribuido. Tales procesadores pueden recibir varios nombres como: sitios, nodos, etc., dependiendo del contexto en que se mencionan.
5.4 Sistemas Distribuidos y la Sociedad
El comportamiento de los usuarios (sociedad) ha variado los últimos años, en los que muchos de ellos ya están introduciendo a este nuevo mundo de tecnología.

El impacto en los sistemas distribuidos dentro de la sociedad ha ayudado a facilitar el trabajo al hombre. Ya que existen medios e interfaces que ayudan a un usuario a interactuar por medio de computadora para realizar infinidades de tareas que anteriormente eran difíciles.Con el uso de ha sido posible el uso de aplicaciones comerciales, aplicaciones de red de área extensa y aplicaciones multimedia.
Esto ha favorecido también al crecimiento económico de una organización o empresa ya sea pública o privada.
Instalar Proxy Squid En Ubuntu Desktop
Objetivo:
En la siguiente práctica se pretende explicar de manera breve como configurar un proxy utilizando en programa Squid en un sistema operativo Linux, esto para desarrollar habilidades en cuento a protección de redes donde uno puede manejar el contenido que usuarios puedan ver o no en su ordenador.
Desarrollo
Paso 1.-entraremos a la terminal de Linux he ingresamos las siguiente línea de código para poder instalar Squid.
sudo apt-get install squid3
Una vez instalado el programa pasaremos a configurar un fichero donde indicaremos en puerto donde se conectara dónde para editar este fichero indicaremos el siguiente código
sudo gedit squid.conf
Donde para nos mostrara el contenido del archivo Squid donde buscaremos las siguientes líneas de código y modificares y agregaremos para que esta quede de tal forma como mostraremos, que a continuación explicare el porqué de las líneas de código a modificar o agregar.
Para empezar se agrega las líneas de código donde en la primera se la dirección IP será la de la máquina que ocupes en mi caso con terminación 85.
En la siguiente se indica que denegara todo lo que está el fichero “noperm”
acl Red src 192.168.1.85/24
acl src noperm deny
acl noway url_regex “/etc/squid/noperm”
http_access deny noway
http_access allow Red
Después confirmaremos el puerto donde filtrara el proxy que en este caso es el puerto 3128
y una memoria cache de 256 MB
Por ultimo modificaremos el cache dir para la dimension de carpetas, en resumidas cuentas nos debe de quedar como se muestra en la figura 1.

(Figura1)
Paso 2.- una vez modificado este fichero pasemos a crear el fichero llamado "noperm"
donde estaran guardadas las palabras o direcciones que bloquearemos , para crearlo pondremos en la terminal:
sudo vi /etc/squid3/noperm
Donde nos parecerá como se muestra en la figura 2, que es nuestro caso filtraremos todo lo que esté relacionado con, ejemplo Myspace y Metroflog, y guardaremos cambios

(Figura 2)
Paso 3.- una vez guardado las palabras reservadas que se utilizaran, pasaremos a reiniciar nuestro servicio Squid para dar paso a lo que sigue, para esto aplicaremos un restart a Squid como se muestra en la figura 3.

(Figura 3)
Paso 4.-una vez reiniciado nuestro servicio Squid nos iremos a configurar nuestro navegador como muestra en la figura 4.en este caso estamos utilizando Firefox como navegador web. La ruta será:
Preferencias>Avanzado>Red>Configurar>Configurar Manual Del Proxy
Ahí es que introduciremos la dirección IP que dimos de alta y el puerto 3128 indicados en el paso 1. y con esto guardamos y listo abra quedado instalado y configurado nuestro proxy Squid para en Ubuntu

(Figura 4)
Con Esto daremos por concluida esta práctica exitosamente, pero antes daremos una demostración de que el proxy si corre bien, mostrado en la figura 5 como al ingresar al navegador configurado y buscaremos en este caso Myspace he intentaremos entrar veremos que como resultado

(Figura 5)
Que este no accede a la página ay que el proxy está corriendo correctamente y no permite el acceso ya que esta página tiene palabras que están en nuestro fichero “noperm” de palabras a filtrar,
Bueno eso sería todo espero que les sea de gran ayuda y puedan aplicarlo ustedes también. Gracias :D
UNIDAD IV: MEMORIA COMPARTIDA DISTRIBUIDA
UNIDAD
4: MEMORIA COMPARTIDA DISTRIBUIDA
Representan la creación hibrida de 2 o más
tipos de computación paralelos, la memoria distribuida en sistemas
multiprocesador y los sistemas distribuidos. Ellos proveen la abstracción de
memoria compartida en sistemas con memorias distribuidas físicamente y
consecuentemente combinan las mejores características de ambos enfoques.
Debido a esto el concepto de memoria
compartida distribuida es reconocido como uno de los enfoques más atractivos
para la creación de sistemas escalables de alto rendimiento de sistemas
multiprocesador.
4.1
CONFIGURACION DE MEMORIA COMPARTIDA DISTRIBUIDA
Los sistemas de memoria compartida
distribuida (DSM) representan la creación hibrida de dos tipos de computación
paralelos: la memoria distribuida en sistemas multiprocesador y los sistemas
distribuidos. Ellos proveen la abstracción de memoria compartida en sistemas
con memorias distribuidas físicamente y consecuentemente combinan las mejores
características de ambos enfoques. Debido a esto, el concepto de memoria
compartida distribuida es reconocido como uno de los enfoques mas atractivos
para la creación de sistemas escalables, de alto rendimiento de sistemas
multiprocesador.
4.1.1
DE CIRCUITO BASADOS EN BUS, ANILLO Y CONMUTADOR.
Multiprocesadores basados en un bus.
Para evitar que dos o más CPU’s intenten el
acceso a la memoria al mismo tiempo, se necesita algún tipo de arbitraje del
bus. El CPU debe pedir permiso para conseguir el bus. La concesión puede
hacerse de forma centralizada, utilizando un dispositivo de arbitraje de bus, o
de forma descentralizada, donde el primer CPU que realice una solicitud en el
bus ganará cualquier conflicto.
La desventaja es la sobrecarga del bus.
Una solución sería equipar a cada CPU con un
caché husmeador.
Un protocolo en particular común es el de
escritura a través del caché. Cuando un CPU lee por primera vez una palabra de
memoria, esa palabra es llevada por el bus y guardada en el caché del CPU
solicitante.
Puede suceder que una palabra en particular
se oculte en dos o más CPU al mismo tiempo.
Operación de lectura.
Si la palabra no esta en el caché, entonces
buscarla en la memoria y copiarla a su caché.
Si la palabra esta en el caché, tomar el dato
de ahí.
Operación de escritura
Si ningún CPU tiene la palabra en su caché,
entonces la palabra es actualizada en memoria, como si el ocultamiento no
hubiera sido utilizado.
Si el CPU (que realiza la escritura) tiene la
única copia de la palabra, se actualiza su caché y también la memoria mediante
el bus.
Si dos o más CPU tienen la palabra, entonces
se actualiza la palabra en el caché y en la memoria, y se invalidan las entradas
de esa palabra en los cahés de los otros CPU. Así la palabra sólo la tendrá la
memoria y un colo caché.
Una alternativa a invalidar otras entradas de
caché es actualizarlas todas, pero esto puede resultar más lento.
Una ventaja de este protocolo es que es fácil
de entender e implantar, la desventaja es que todas las escrituras utilizan el
bus.
Existe otro tipo de protocolos como el
protocolo de membresía. Una versión de este protocolo plantea lo siguiente. Se
manejan bloques de caché, cada uno de los cuales puede estar en uno de los
siguientes estados:
INVALIDO: Este bloque de caché no contiene
datos válidos.
LIMPIO: La memoria está actualizada, el
bloque puede estar en otros cachés.
SUCIO: La memoria es incorrecta; ningún otro
caché puede contener al bloque.
La palabra permanece el estado SUCIO hasta
que se elimine del caché donde se encuentra en la actualidad por razones de
espacio. En este momento, desaparece de todos los cachés y se escribe en la
memoria. Este protocolo tiene tres propiedades importantes:
La consistencia se logra haciendo que todos
los cachés husmeen el bus.
El protocolo se integra dentro de la unidad
de administración de memoria.
Todo el algoritmo se realiza en un ciclo de
memoria.
La desventaja es que no funciona para
multiprocesadores de mayor tamaño y nada es válido para la memoria compartida
distribuida.
Multiprocesadores basados en un anillo
Ejemplo: Memnet
En Memnet, un espacio de direcciones se
divide en una parte privada y una compartida.
La parte compartida se divide en bloques de
32 bytes, unidad mediante la cual se realizan las transferencias entre las
máquinas.
Las máquinas Memnet están conectadas mediante
un anillo de fichas modificado. El anillo consta de 20 cables paralelos, que
juntos permiten enviar 16 bits de datos y 4 bits de control cada 100
nanosegundos, para una velocidad de datos de 160 Mb/seg.
Un bloque exclusivo de lectura puede estar
presente en varias máquinas, uno de lectura-escritura debe estar presente en
una sola máquina.
Los bits en el dispositivo Memnet indican uno
o más de los siguientes estados:
·
VALIDO:
El bloque esta presente en el caché y está actualizado.
·
EXCLUSIVO:
La copia local es la única.
·
ORIGEN:
Se activa si ésta es la máquina origen del bloque.
·
INTERRUPCION:
Se utiliza para forzar interrupciones.
·
POSICION:
Indica la localización del bloque en el caché si esta presente y es válido.
·
Protocolo
Memnet.
·
Lectura.
Cuando un CPU desea leer una palabra de la
memoria compartida, la dirección de memoria por leer se transfiere al
dispositivo Memnet, el cual verifica la tabla del bloque para ver si está
presente. Si es así, la solicitud es satisfecha de inmediato. En caso
contrario, el dispositivo Memnet espera hasta capturar la ficha que circula;
después, cooca un paquete de solicitud en el anillo y suspende el CPU. El
paquete de solicitud contiene la dirección deseada y un campo vacío de 32
bytes.
Cada dispositivo Memnet en el anillo verifica
si tiene el bloque. De ser así, coloca el bloque en el campo vacío y modifica
el encabezado del paquete para inhibir la acción de las máquinas posteriores.
Si el bit exclusivo del bloque está activo,
se limpia. Cuando el paquete regresa al emisor, se garantiza que contiene al
bloque solicitado. El CPU que envía la solicitud guarda el bloque, satisface la
solicitud y libera al CPU.
Si la máquina solicitante no tiene espacio
libre en su caché para contener el bloque recibido, entonces toma al azar un
bloque oculto y lo envía a su origen, con lo que libera un espacio de caché.
Los bloques cuyo bit origen están activados nunca se eligen, pues se encuentran
en su origen.
Escritura.
Tenemos tres casos:
a) Si
el bloque contiene la palabra por escribir está presente y es la única copia en
el sistema, (el bit exclusivo esta activado) la palabra solo se escribe de
manera local.
b) Si
esta presente el bloque, pero no es la única copia, se envía primero un paquete
de invalidación por el anillo para que las otras máquinas desechen sus copias
del bloque por escribir. Cuando el paquete de invalidación regresa al
solicitante, el bit exclusivo se activa para ese bloque y se procede a la
escritura local.
c) Si
el bloque no está presente, se envía un paquete que combina una solicitud de
lectura y una de invalidación. La primera máquina que tenga el bloque lo copia
en el paquete y desecha su copia. Todas las máquinas posteriores solo desechan
el bloque de sus cachés. Cuando el paquete regresa al emisor, éste lo guarda y
escribe en él.
La ventaja de este protocolo es que se puede
aplicar a multicomputadoras.
Principales Aproximaciones a DSM
Existen tres aproximaciones a la
implementación de memoria compartida distribuida, las cuales involucran el uso
de hardware, memoria virtual o bibliotecas de soporte. Estos no son mutuamente
exclusivas necesariamente.
Basada en hardware. Por ejemplo Dash y PLUS.
El conjunto de procesadores y los módulos de memoria están conectados vía una
red de alta velocidad. El problema es la escalabilidad.
Basado en páginas. Poe ejemplo Ivy, Munin,
Mirage, Clouds, Choices, COOL y Mether, todas implanta DSM como una región de
memoria virtual que ocupa el mismo rango de dirección en el espacio de direcciones
de cada proceso participante. En cada caso el kernel mantiene la consistencia
de datos dentro de las regiones DSM como parte del manejo de fallo de página.
Basado en bibliotecas. Algunos lenguajes o
extensiones de lenguaje tales como ORCA y Linda soportan formas de DSM.
4.2
MODELOS DE CONSISTENCIA
La duplicidad de los bloques compartidos
aumenta el rendimiento, pero produce un problema de consistencia entre las
diferentes copias de la página en caso de una escritura.
Si con cada escritura es necesario actualizar
todas las copias, el envío de las páginas por la red provoca que el tiempo de
espera aumente demasiado, convirtiendo este método en impracticable
4.2.1
ESTRICTA, CASUAL, SECUENCIAL, DEBIL, DE LIBERACION Y DE ENTRADA.
CONSISTENCIA CASUAL: La condición a
cumplir para que unos datos sean causalmente consistentes es:
• Escrituras
que están potencialmente relacionadas en forma causal deben ser vistas por
todos los procesos en el mismo orden.
• Escrituras
concurrentes pueden ser vistas en un orden diferente sobre diferentes máquinas.
Es permitida con un almacenamiento
causalmente consistente, pero no con un almacenamiento secuencialmente
consistente o con un almacenamiento consistente en forma estricta.
CONSISTENCIA SECUENCIAL: La consistencia
secuencial es una forma ligeramente más débil de la consistencia estricta.
Satisface la siguiente condición:
El resultado de una ejecución es el mismo si
las operaciones (lectura y escritura) de todos los procesos sobre el dato
fueron ejecutadas en algún orden secuencial
a) Un dato almacenado secuencialmente
consistente.
b) Un dato almacenado que no es
secuencialmente consistente.
CONSISTENCIA DÉBIL: Los accesos a
variables de sincronización asociadas con los datos almacenados son
secuencialmente consistentes.
Propiedades
No se permite operación sobre una variable de
sincronización hasta que todas las escrituras previas de hayan completado.
No se permiten operaciones de escritura
o lectura sobre datos hasta que no se hayan completado operaciones
previas sobre variables de sincronización.
CONSISTECIA DE LIBERACION: Se basa en el
supuesto de que los accesos a variables compartidas se protegen en secciones
críticas empleando primitivas de sincronización, como por ejemplo locks. En tal
caso, todo acceso esta precedido por una operación adquiere y seguido por una
operación release. Es responsabilidad del programador que esta propiedad se
cumpla en todos los programas.
4.3 MCD
EN BASE A PAGINAS
El esquema de MCD propone un espacio de
direcciones de memoria virtual que integre la memoria de todas las computadoras
del sistema, y su uso mediante paginación. Las páginas quedan restringidas a
estar necesariamente en un único ordenador. Cuando un programa intenta acceder
a una posición virtual de memoria, se comprueba si esa página se encuentra de
forma local. Si no se encuentra, se provoca un fallo de página, y el sistema
operativo solicita la página al resto de computadoras.
4.3.1
DISEÑO, REPLICA, GRANULARIDAD, CONSISTENCIA, PROPIETARIO Y COPIAS.
El sistema operativo, y en el caso del
protocolo de consistencia de entrada, por acciones de sincronización explícitas
dentro del código del usuario. El hecho que la especificación se encuentre
dispersa dificulta tanto la incorporación de nuevos protocolos de consistencia
como la modificación de los ya existentes, debido a que los componentes tienen
además de su funcionalidad básica responsabilidades que no les corresponden.
4.4 MCD
EN BASE A VARIABLES
La comparticion falsa se produce cuando dos
procesos se pelean el acceso a la misma pagina de memoria, ya que contiene
variables que requieren los dos, pero estas no son las mismas. Esto pasa por un
mal diseño del tamaño de las paginas y por la poca relación existente entre
variables de la misma pagina.
En los MCD basados en variables se busca
evitar la comparticion falsa ejecutando un programa en cada CPU que se comunica
con una central, la que le provee de variables compartidas, administrando este
cualquier tipo de variable, poniendo variables grandes en varias paginas o en
la misma pagina muchas variables del mismo tipo, en este protocolo es muy
importante declarar las variables comparitdas.
4.5 MCD
EN BASE A OBJETOS.
Una alternativa al
uso de páginas es tomar el objeto como base de la transferencia de memoria.
Aunque el control de la memoria resulta más complejo, el resultado es al mismo
tiempo modular y flexible, y la sincronización y el acceso se pueden integrar
limpiamente.
44Otra de las restricciones de este modelo es
que todos los accesos a los objetos compartidos han de realizarse mediante
llamadas a los métodos de los objetos, con lo que no se admiten programas no
modulares y se consideran incompatibles
martes, 27 de octubre de 2015
UNIDAD III: PROCESOS Y PROCESADORES EN SISTEMAS DISTRIBUIDOS
3.1 PROCESOS Y PROCESADORES CONCEPTOS
BÁSICOS.
Un proceso es un concepto manejado por
el sistema operativo que consiste en el conjunto formado por: Las
instrucciones de un programa destinadas a ser ejecutadas por
el microprocesador. Su estado de ejecución en un momento dado, esto es, los
valores de los registros de la CPU para dicho programa. Su memoria de
trabajo, es decir, la memoria que ha reservado y sus contenidos.
Los procesadores distribuidos se pueden
organizar de varias formas:
v Modelo de estación de trabajo.
v Modelo de la pila de
procesadores.
v Modelo híbrido.
3.2 HILOS Y MULTIHILOS
v Threads llamados procesos
ligeros o contextos de ejecución.
v Típicamente, cada thread
controla un único aspecto dentro de un programa.
v Todos los threads comparten los
mismos recursos, al contrario que los procesos en donde cada uno tiene su
propia copia de código y datos (separados unos de otros).
Los sistemas operativos generalmente
implementan hilos de dos maneras:
} MULTIHILO APROPIATIVO
Permite al sistema
operativo determinar cuándo debe haber un cambio de contexto.
La desventaja de esto
es que el sistema puede hacer un cambio de contexto en un momento inadecuado,
causando un fenómeno conocido como inversión de prioridades y otros problemas.
} MULTIHILO COOPERATIVO
Depende del mismo
hilo abandonar el control cuando llega a un punto de detención, lo cual puede
traer problemas cuando el hilo espera la disponibilidad de un recurso.
3.3 MODELOS DE PROCESADORES
La historia de los microprocesadores comienza
en el año 1971, con el desarrollo por parte de Intel del procesador 4004, para
facilitar el diseño de una calculadora.
La época de los PC (Personal Computer),
podemos decir que comienza en el año 1978, con la salida al mercado del
procesador Intel 8086.
3.3.1 DE ESTACIÓN DE TRABAJO.
v El sistema consta de estaciones
de trabajo (PC) dispersas conectadas entre sí mediante una red de área local
(LAN).
v Pueden contar o no con disco
rígido en cada una de ellas.
Uso de los discos en las estaciones de
trabajo:
Sin disco: Bajo costo, fácil
mantenimiento del hardware y del software, simetría y flexibilidad.
Con disco: Disco para paginación y
archivos de tipo borrador:
Reduce la carga de la red respecto del caso
anterior.
Alto costo debido al gran número de discos
necesarios.
3.3.2 MODELO DE PILA DE PROCESADORES
Este modelo basa su funcionamiento en la
teoría de colas.
En general este modelo puede reducir
significativamente el tiempo de espera al tener una sola cola de procesadores a
repartir.
La capacidad de cómputo se puede gestionar de
mejor forma si se tiene micros con mayores capacidades.
3.3.3 HÍBRIDO.
Los sistemas híbridos combinan una variedad
de buses de instrumentación y plataformas en un sistema. A través de sistemas
híbridos, se puede lograr la flexibilidad para combinar los instrumentos
independientemente del bus, permitiendo elegir los instrumentos más adecuados
para sus necesidades de aplicación.
Características de los Sistemas
Híbridos.
v Combina las mejores
características del modelo de estación de trabajo y de pila de procesadores
teniendo un mejor desempeño en las búsquedas y mejor uso de los recursos
v Aumento en flexibilidad, los
sistemas híbridos proporcionan una longevidad mayor para el sistema de pruebas
con la habilidad para usar hardware y software existente, y aún así incorporar
nuevas tecnologías con mayor desempeño y menor costo
3.4 ASIGNACIÓN DE PROCESADORES.
Esta estrategia consiste como su
nombre lo indica, en dedicar un grupo de procesadores a una
aplicación mientras dure esta aplicación, de manera que cada hilo de la
aplicación se le asigna un procesador.
3.4.1 MODELOS Y ALGORITMOS CON SUS ASPECTOS
DE DISEÑO E IMPLANTACIÓN.
Los principales Aspectos son:
v Algoritmos deterministas vs.
heurísticos.
v Algoritmos centralizados vs.
distribuidos.
v Algoritmos óptimos vs.
subóptimos.
v Algoritmos locales vs. globales.
v Algoritmos iniciados por el
emisor vs. iniciados por el receptor.
3.5 COPLANIFICACION
Concepto de coplanificación:
Ø Toma en cuenta los patrones de
comunicación entre los procesos durante la planificación
Ø Debe garantizar que todos los
miembros del grupo se ejecuten al mismo tiempo.
Ø Cada procesador debe utilizar un
algoritmo de planificación ROUND ROBIN.
3.6 TOLERANCIA A FALLOS
La tolerancia a fallos es un aspecto crítico
para aplicaciones a gran escala, ya que aquellas simulaciones que pueden tardar
del orden de varios días o semanas para ofrecer resultados deben tener la
posibilidad de manejar cierto tipo de fallos del sistema o de alguna tarea de
la aplicación.
3.7 SISTEMAS DISTRIBUIDOS DE TIEMPO REAL
Sistemas distribuidos
Un sistema distribuido está formado por
un conjunto de computadores autónomos conectados para conseguir
unobjetivo común
Ventajas:
v rendimiento
v fiabilidad
v cercanía a los elementos del
entorno físico
v flexibilidad
v Características:
v 1. Se activan por evento o por
tiempo.
v 2. Su comportamiento debe
ser predecible.
v 3. Debe ser tolerante a
fallas.
v 4. La comunicación en los
sistemas distribuidos de tiempo real debe de ser de alto desempeño.
CLASIFICACIÓN
v Los sistemas de tiempo real se
clasifican en general en dos tipos dependiendo de los serio de sus tiempos
limites y de las consecuencias de omitir uno de ellos.
v Sistema de tiempo real suave: significa
que no existe problema si se rebasa un tiempo.
v Sistema de tiempo real duro: es
aquel en el que un tiempo límite no cumplido puede resultar catastrófico.
miércoles, 21 de octubre de 2015
Instalar Zabbix En Linux Server
Hola amigos como hoy les dejare un pequeño manual de como instalarse Zabbix de la manera mas sensilla utilizando linux server .
Para aquellos que no sepan que es Zabbix les explicare, Zabbix es un Sistema de Monitoreo de Redes creado por Alexei Vladishev. Está diseñado para monitorear y registrar el estado de varios servicios de red, Servidores, y hardware de red.
Usa MySQL, PostgreSQL, SQLite, Oracle o IBM DB2 como base de datos.
Iniciamos La Instalacion De Ubuntu Server.

Diremos que "NO" y elegiremos "Español" para que nos aplique el teclado “es” (español).
Después de esperar un poco mientras se configura y se detecta el hardware, uno de los últimos pasos que hará en el proceso será intentar obtener mediante DHCP una configuración de red que se realizará automáticamente en caso de existir un servidor de dicho servicio.
Ahora debemos ponerle un nombre de red a nuestro servidor por ejemplo “ServidorCEP”.
Es el momento de seleccionar la zona horaria que en nuestro caso es "Mexico”.
Ahora llega uno de los puntos importantes, el particionado del disco duro.
En este momento debemos elegir si queremos que el programa de instalación nos haga un particionado asistido que nos puede ayudar, o hacerlo manualmente. Nosotros lo haremos manualmente ya que tenemos claro desde el principio como queremos las particiones del disco.Seleccionamos nuestro disco duro en este caso el de la máquina virtual con una capacidad de 8,6GB.
Como el disco está vacío, es necesario crear una nueva tabla de particiones
Seleccionamos el espacio libre para empezar a crear las particiones
Vamos a crear un total de tres particiones primarias para el directorio raíz /, para /home y para swap.
Empezamos a crear la primera de las particiones:
Como seguramente tengamos espacio de sobra en nuestros discos duros asignaremos de los 8GB (8,6BG para ser exactos en mi máquina virtual) que hemos dejado para nuestro sistema 4GB (4,6BG en mi caso) para esta partición que es donde residirá el directorio raíz del sistema, asegurándonos que no nos va a faltar espacio en un futuro aunque sigamos añadiendo servicios a nuestro servidor. Dependiendo de las necesidades de cada uno, el tamaño del disco virtual y las particiones se pueden variar a las que veremos en el curso. La partición será primariaY estará ubicada al principio del espacioEl punto de montaje de la partición a será el directorio raíz como vemos y el sistema de archivos el ext4 usado en sistemas Linux (si somos usuarios de Windows estaremos familiarizados con los sistemas FAT32 y NTFS). Seleccionamos “Se ha terminado de definir la partición”.Ahora crearemos una segunda partición en el espacio libre que nos queda, en la que el punto de montaje será el/home. Para ello repetimos los pasos anteriores seleccionando partición primaria situada al principio y sistema de archivos ext4, con la diferencia de que el punto de montaje será el /home.
Para esta partición asignaremos 3GB,
Terminamos de definir la partición.
Ahora seleccionamos otra vez el espacio libre para crear la partición que usaremos como área de intercambio, swap. El área de intercambio se usa en los sistemas operativos para usar partes del disco duro como si de memoria RAM se tratase, consiguiendo así disponer si fuera necesario de una mayor memoria en el sistema. Lógicamente la memoria RAM es mucho más rápida que los discos duros actuales (incluso más que los novedosos discos sólidos SSD), por lo que cuando se recurre mucho a esta “virtualización” de memoria del disco duro, el rendimiento del sistema se resiente.Asignamos el resto (casi 1GB) para esta partición que como norma general se le suele dejar el doble de la memoria RAM que dispongamos, en nuestro caso le habíamos dejado 512MB para el sistema y por eso le dejamos 1GB. Esto puede variar si le hemos dejado más de 512MB de memoria a nuestra máquina virtual. Si por ejemplo le hemos dejado 1GB a la memoria virtual, dejaremos 2GB para área de intercambio. Esta regla no siempre es del todo adecuada, sobre todo en sistemas con gran cantidad de memoria RAM en los que por lo general no es necesario reservar el doble para swap, pudiendo dejar menos cantidad.Repetimos los pasos anteriores seleccionando partición primaria y situada al principio.
Cuando llegamos a la pantalla resumen debemos cambiar el tipo de archivos por “área de intercambio”.
Vemos el resumen de particiones hasta ahora observando que tenemos que tener las tres particiones dos de ellas con el sistema de archivos ext4 y la otra como swap que usará el sistema como memoria virtual en caso de agotar la memoria física.
Tendremos que esperar a que se realicen los cambios y a que se instale el programa base de instalación.
Ya tenemos lo esencial para empezar a configurar algunos aspectos del sistema.
El primero de los aspectos que tendremos que introducir es el nombre completo de usuario. En mi caso enrique brotons
Ahora escribiremos el nombre de usuario para el sistema. Este nombre no debe llevar separaciones y recomiendo que sea en minúscula ya que Linux sí diferencia la mayúscula de la minúscula y como lo usaremos en muchas ocasiones para loguearnos en el sistema, nos agilizará no tener que estar cambiando entre ellas.
Tenemos que poner una contraseña para nuestro usuario. Las normas de contraseñas seguras aconsejan mezclar en la misma contraseña de al menos ocho dígitos, números, símbolos, minúsculas y mayúsculas. Pero para seguir el curso podemos seleccionar cualquiera siempre y cuando nos acordemos, o mejor aún, apuntemos tanto el usuario como la contraseña en algún sitio.
Si vuestra contraseña es considerada débil el sistema os avisará antes de aceptarla. En nuestro, caso si el sistema es sólo para seguir el curso podemos aceptarla sin problemas. Si en un futuro se usará el curso para montar un servidor en una red de un centro educativo sería recomendable usar una clave segura de cara a posibles ataques como los basados en fuerza bruta.
Debemos elegir entre cifrar la carpeta personal lo que aportará un paso más de seguridad al sistema, o no hacerlo. Para el curso elegiremos NO, al no ser necesario un grado alto de seguridad.
Se empezará con la configuración del gestor de paquetes “apt” y se nos preguntará si usamos un servidor proxy para acceder a la red. Si no usamos ninguno lo dejaremos en blanco. Si estamos accediendo a la red a través de un proxy debemos ponerle los datos del mismo en el formato que nos indica. En caso de no saber estos datos, tendremos que consultarle al administrador del mismo, o copiarlos de algún ordenador de la red que este configurado.
La siguiente pregunta es importante porque nos pregunta como deseamos llevar a cabo las actualizaciones dándonos a elegir entre automáticas, manuales, o usando Landscape. Si no vamos a llevar un control periódico de las actualizaciones del servidor, lo más recomendable es dejarlo en automáticas, de manera que siempre que el servidor tenga conexión y haya actualizaciones de seguridad pendientes se actualizará
Ahora podemos elegir que componentes adicionales queremos instalar. Nosotros marcaremos usando la “barra espaciadora”, OpenSHH server, LAMP server, Samba file server y DNS server. Una vez marcados aceptaremos con la tecla “Intro”.

Como hemos elegido agregar LAMP durante la instalación, debemos introducir una contraseña para el usuario root de la base de datos de MySQL. Tengamos en cuenta que esta contraseña no tiene porque ser la misma que la que hemos definido para el usuario de Ubuntu que creamos anteriormente, aunque para seguir el curso podemos usar siempre las mismas.

Es importante recordar, o mejor apuntar, la contraseña de root para MySQL que acabamos de introducir, ya que luego la necesitaremos.
Después de un rato instalando los paquetes que conformaran el sistema operativo, el instalador detecta que es el único sistema que hay instalado y nos pregunta que si queremos instalar el gestor de arranque GRUB en el registro principal del primer disco duro (MBR). Respondemos que SÍ, presuponiendo que el Ubuntu Server no va a estar en una máquina con más sistemas operativos instalados.
Hemos finalizado la instalación y solo falta reiniciar para arrancar por primera vez nuestro sistema servidor. Si hemos usado un CD para la instalación debemos extraerlo y si lo hemos instalado directamente desde la imagen ISO no tendremos que hacer nada.
Para intalar Zabbix
Instale los últimos paquetes de la versión, este contiene la configuración del repositorio.
sudo wget http://repo.zabbix.com/zabbix/2.2/ubuntu/pool/main/z/zabbix-release/zabbix-release_2.2-1+trusty_all.deb sudo dpkg -i Zabbix-release_2.2-1 + trusty_all.deb sudo update apt-getInstalar los siguientes paquetes, que se instalará el servidor Zabbix y web con MySQL.
sudo apt-get install Zabbix de servidor mysql Zabbix-frontend-php
Paso 1: Configurar la contraseña de root para MySQL
Paso 2: Confirmar la contraseña de root.
Paso 3: Al lado de la pantalla, se le pedirá que configure la base de datos para el Zabbix, que aceptar o cancelarla. Aquí elegí sí para la configuración de base de datos automático.
Paso 4: Introduzca la contraseña para el usuario de base de datos "Zabbix" (Zabbix usuario será creado por el instalador), esta contraseña se ha introducido al configurar Zabbix.
Paso 5: Confirmar la contraseña para el usuario de base de datos.
La siguiente sección de solución de problemas sólo se aplica a los que enfrenta el error 404 no encontrado al acceder url configuración Zabbix.
Solución de problemas:
Después de configurar la base de datos, cuando traté de acceder a la url configuración Zabbix (http: // tu-dirección-ip / Zabbix). Tengo 404 no se encuentra la página, después de un montón de búsqueda de Google;Encontrar nada. Más tarde me decidí a comprobar los archivos creados por el paquete, en última encontré apache.conf archivo en / etc / Zabbix.
Copie el archivo en el directorio apache2 apache.conf
sudo cp /etc/zabbix/apache.conf /etc/apache2/sites-enabled/zabbix.conf
Editar archivo de configuración copiado la zona horaria. Cambie el date.timezone de acuerdo a su zona horaria. Reinicie el servicio apache2.Después de realizar los pasos anteriores, yo era capaz de acceder la url sin ningún problema. Configuración Zabbix: Visite el siguiente URL para iniciar la creación de la http Zabbix: // tu-dirección-ip / Zabbix. Haga clic en Siguiente para continuar.Configuración Zabbix comprobará los requisitos previos, le dará el estado como a continuación.Ingrese la información de base de datos.Configurar la información del servidorEcha un vistazo a el resumen de la instalación Termine la configuración.Ingresar con credenciales por defecto (Admin / Zabbix)Esta forma del salpicadero Zabbix parezca.¡Eso es todo!. Ha configurado correctamente el servidor Zabbix,







Suscribirse a:
Entradas (Atom)